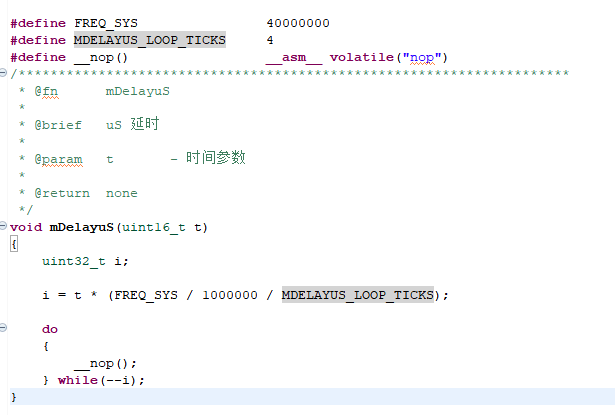
发现sdk自带了微秒和毫秒延时函数,但是没有发现纳秒级延时(不需要精确到1ns,只要比如60ns或者120ns的倍数即可)
于是我想到了用for循环来实现纳秒延时,遗憾的是需要知道指令周期才能确定,for循环实际执行了多久
比如
for(int?i=100;?i>0;--i)
asm?volatile("nop");
汇编代码是:
? ?li a5,100
.j: nop
? ?addi a5,a5,-1
? ?bnez a5,.j
这4行代码,目前确定第二行 nop 需要 1个指令周期 6.94ns(144M频率)
其他3行代码,并不知道具体执行指令的周期,也就没法计算for循环实际需要执行多久
是否有什么数据手册,可以提供比如 li 指令 addi 指令 bnez等指令的执行周期
这样,就能编写一个宏,实现 比如delay300ns,delay600ns这样的功能
热门产品 :
CH182: 以太网PHY收发器芯片